胖鼠采集(Fat Rat Collect) 是一款能够帮助你网站自动化的工具.自动采集,自动发布,省心省力,由作者Fatrat独立开发的一款开源WordPress采集插件。


通过简单学习掌握爬虫技巧是胖鼠采集的核心,简单的采集规则让不懂代码的同学,下面带领大家来创建一个采集规则,以下图片都可以点击放大,请认真阅读。
采集规则包含两个教程,以下内容为图文教程,如需视频教程,请在文章底部下载
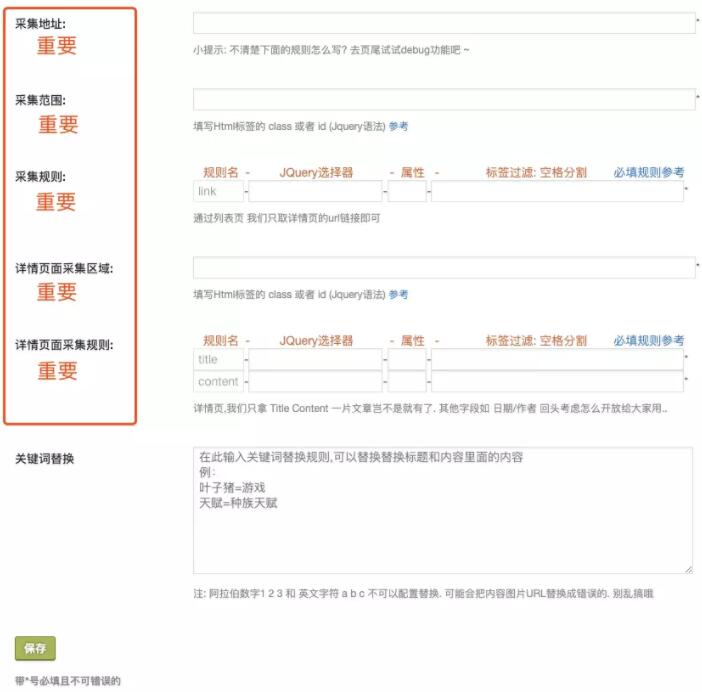
采集最重要的为5个内容步骤
- 采集地址: 大家采集目标页面的地址
- 采集范围: 你要采集目标页面的哪一块数据
- 采集规则: Jquery选择器,选择页面上的区域
- 详情页采集范围: 同上
- 详情页采集规则: 同上
知识科普
- 在 html 中
- class 对应 Jquery 的 .
- id 对应 Jquery 的 #
- 填写采集规则过程中
- >代表递进层关系
- Jquery 的 eq 语法 a:eq(1) 意是取 所在区域的 第二个 a
【 注:代码中从 0 开始(只有一个 a标签 可以只填 a 即可)】
- 在填写 Jquery 语法中
- href 基本指 a 标签的 href 属性(这个属性存储的是点击后跳转地址)
- text 取区域的文本 ,一般用于标题
- html 取区域的所有的html 一般用到取内容,内容比较多。且内容有排版里面有 image css js 很多东西 。所以要拿到所有的原始html
- 过滤规则中
- a 就是去除掉区域所有a标签跳转功能。保留文字
- -a 删除a标签 包括删除a标签里面包含的内容 (不建议使用,因为有些图片是在a里面的 删除a 里面的 图片也没了。)
- -div 删除所有div
- -p 同上
- -b 同上
- -span 同上
- -p:first 删除第一个 p标签
- -p:last 删除最后一个 p标签
- -p:eq(-2) 删除倒数 二个p
- -p:eq(2) 删除正数 二个p
- 就是这个套路…
下面的例子中每个选择器都有 . 或者 # 大家放大图仔细看。不要拉下这些小符号了
现在就正式开始,如遇不理解的地方,请多琢磨多尝试!图4为最终配置图,请多对比!
采集地址
目标采集目标地址(举例的网址): 这是国内某游戏新闻列表页https://xx.qq.com/webplat/info/news_version3/154/2233/3889/m2702/list_1.shtml
打开页面,在页面中 点击右键->检查 即可出现下方的框框。可看到页面的源代码
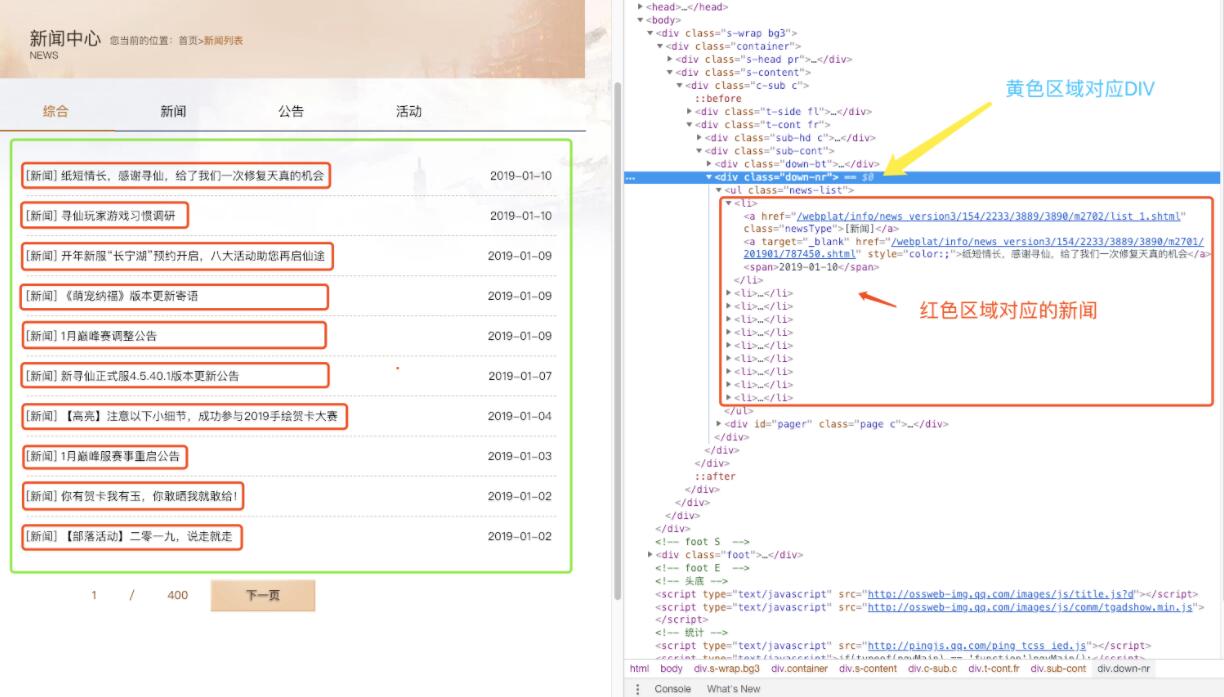
采集范围
- 如图1所示:他每页有十篇新闻
- 黄色区域就是我们本页面所有文章所在的范围
- 黄色区域 对应右侧的代码 区域 class = down-nr
- 解释: 加上 ul li 会循环每一个文章所在的区域。达到了我们列表批量采集的目的
- 注意: 这一步 请务必使用debug功能测试。(下面有介绍如何使用)
- 最终列表采集范围结果: .down-nr>ul>li
- 列表十篇文章的区域找到了,下面就找找十篇文章区域,所对应的文章链接吧
- 因为拿到具体的文章链接我们就能去采集每篇文章的内容啊!
- 恭喜完成第一步
采集规则
现在我们已经定位到了文章区域,我们现在要找到区域中文章的链接,来编写采集规则

一般的文章区域只有一个a就是文章地址。但是这个例子不太一样,大家图2中观察 li 里面的文章区域有两个 a
- 第一个a是新闻列表页地址 第二个a才是我们需要的文章地址
- 我们用 Jquery 的 eq 语法 a:eq(1) 意是取 所在区域的 第二个 a
- 注:代码中从 0 开始(只有一个 a标签 可以只填 a 即可),
- 注:如果目标站链接是相对链接。程序会自动补全的
- 最终列表采集规则: a:eq(1) href
- href 意思选择a标签的 href属性(就是文章地址)
- 注: 请使用Debug功能(下面有介绍如何使用)
- 第二步完成了
详情页面 采集区域 和 采集规则
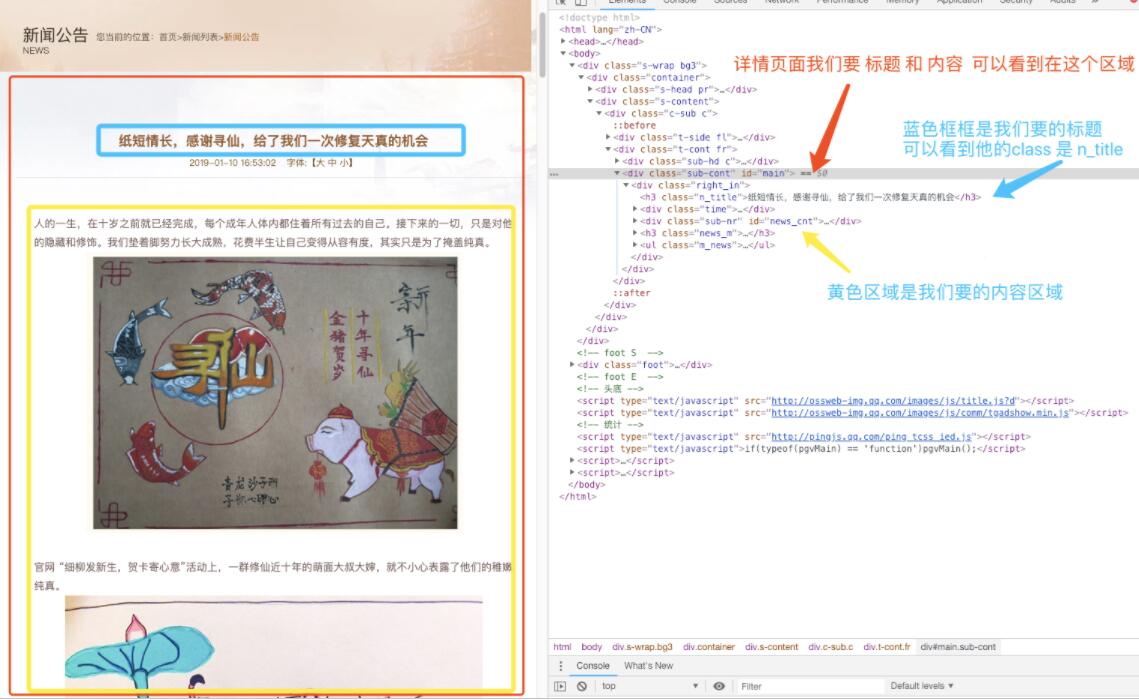
根据上面的描述,我们基本现在掌握了一定技巧,那么现在采集区域的说明就简单了,大家看图3和图4对比 。注:请使用Debug功能,每一步都使用debug功能看结果。
- 详情采集范围 .sub-cont
- 解释: 看图3 .sub-cont 包括了 标题和内容 是他们的父级区域 选择这个区域可
- 详情采集规则 title = .n_title
- 详情采集规则 content = .sub-nr
- 解释: 看图3 .n_title 是文章的标题
- 解释: 看图3 .sub-nr 使文章的内容
- href 基本指 a 标签的 href 属性(这个属性存储的是点击后跳转地址)
- text 取区域的文本 ,一般用于标题
- html 取区域的所有的html 一般用到取内容,内容比较多。且内容有排版里面有 image css js 很多东西 。所以要拿到所有的原始html
所以我们应该得出下面的图4配置

标签过滤(关键词替换)
- a 就是去除掉区域所有a标签跳转功能。保留文字
- -a 删除a标签 包括删除a标签里面包含的内容 (不建议使用,因为有些图片是在a里面的 删除a 里面的 图片也没了。)
- -div 删除所有div
- -p 同上
- -b 同上
- -span 同上
- -p:first 删除第一个 p标签
- -p:last 删除最后一个 p标签
- -p:eq(-2) 删除倒数 二个p
- -p:eq(2) 删除正数 二个p
- 就是这个套路…
标签过滤支持所有 Jquery 语法,灰常强大。能帮你处理各种杂乱的数据
请看下图。只是一部分过滤方法。更多请自行百度。
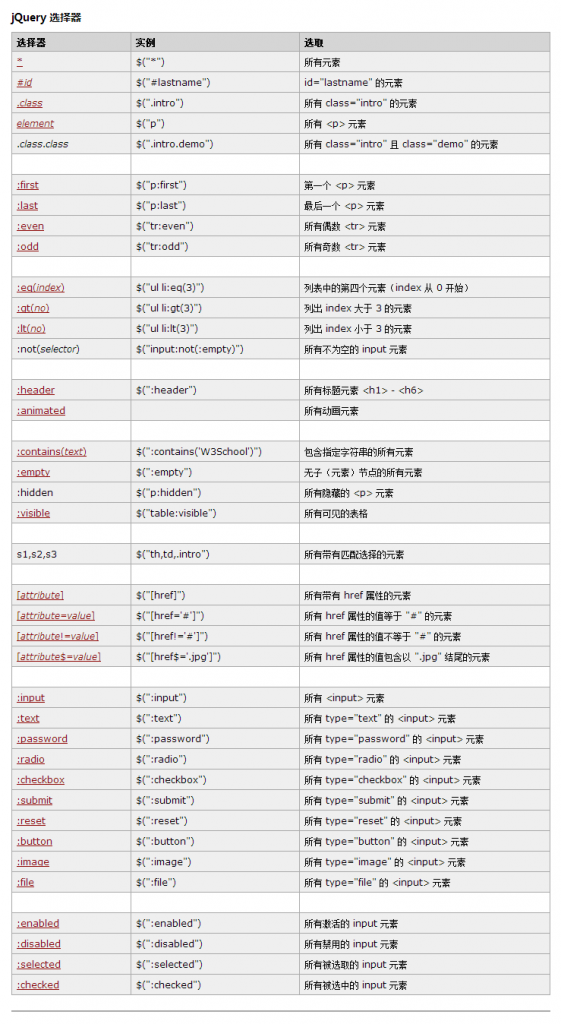
请看上图,只是过滤的一部分。大家自行百度,胖鼠采集过滤功能很强大。新手可以导入默认例子品尝。全部都是配好的规则直接用
Debug功能使用方法
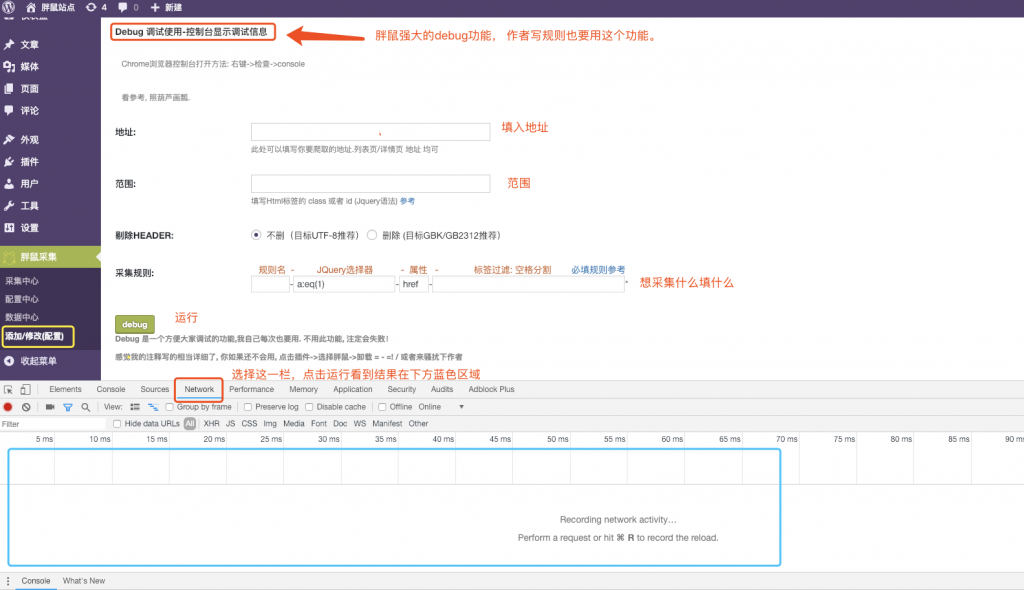
下图7为实战演示
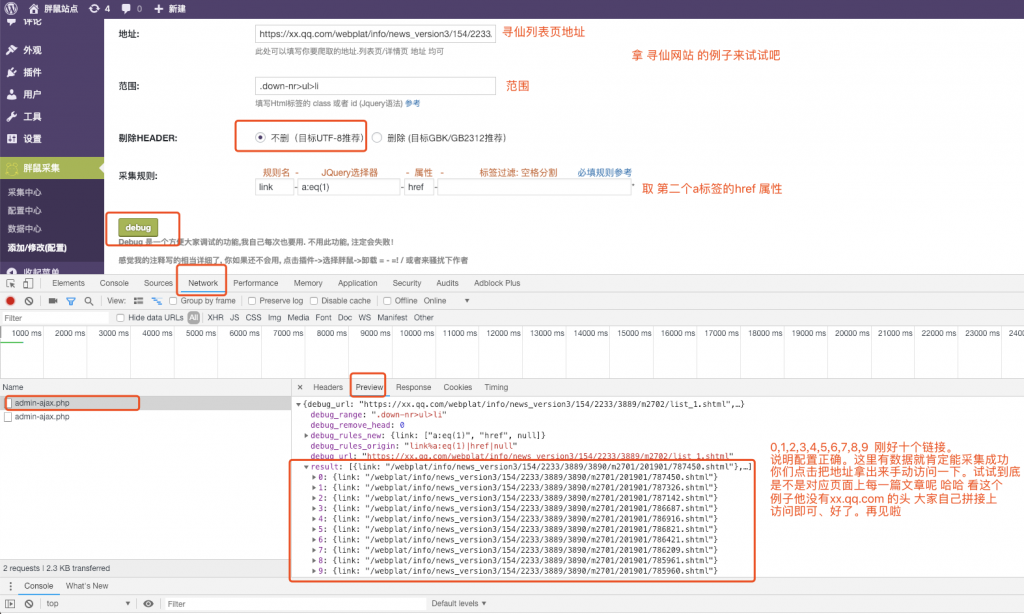
上面是debug是测试采集10条link有没有采集成功。有了link之后就可以采集详情页面了
大家同样要使用debug功能 测试 详情页 title content 是否可以获取正确。
测试过 link title content 三个规则数据都对了。那么采集应该就十拿九稳啦。
一次花点时间配一次 就可以一直使用。希望大家花一点点时间学习一下。
这个网站只是其中一个例子。
目标站 html 与这种不同,可以动动脑筋,多改改。用Debug多看看结果
视频教程下载
原创文章,作者:Tony,如若转载,请注明出处:https://www.xxside.com/1878.html
思德心语,壹群:799239814